In the ongoing debate about the potential impact of AI on the job market, particularly within the technology sector, I believe it’s important to address the widespread concerns that AI might soon render certain professions obsolete. Among these, the role of engineers is often spotlighted, with many speculating that advanced AI systems (specifically generative AI) could one day replace human ingenuity in the field. As an engineer myself, I’d like to offer a perspective on why I believe this scenario is far from imminent, and why the role of engineers will remain crucial for the foreseeable future.
“Peak AI”
Recently, a Computerphile video delved into a study that highlighted an emerging plateau in AI models, specifically relating to “Zero-Shot” performance. This in and of itself is not to say we are at any sort of peak but it does highlight the insatiable hunger these models have for data. As the study concludes, “…an exponential need for training data … implies that the key to “zero-shot” generalization capabilities under large-scale training paradigms remains to be found”.
To be clear, “Zero-Shot” refers to the ability of an AI to make a decision on something it has never seen before, based on information it has already learned. For example, if you are shown several pictures of a horse and told that a zebra is a horse with stripes, you will likely be able to identify one despite never actually seeing one before. Fundamentally, this is what Zero-Shot refers to in AI.
The study suggests that as the datasets used to train these models continue to expand, the gains in performance are increasing logarithmically with respect to Zero-Shot performance—or in some cases, even regressing. This development suggests that we may be approaching the limits of what current generative AI can achieve without an unrealistic amount of data, especially in areas requiring precision and deep contextual understanding—qualities essential in engineering.
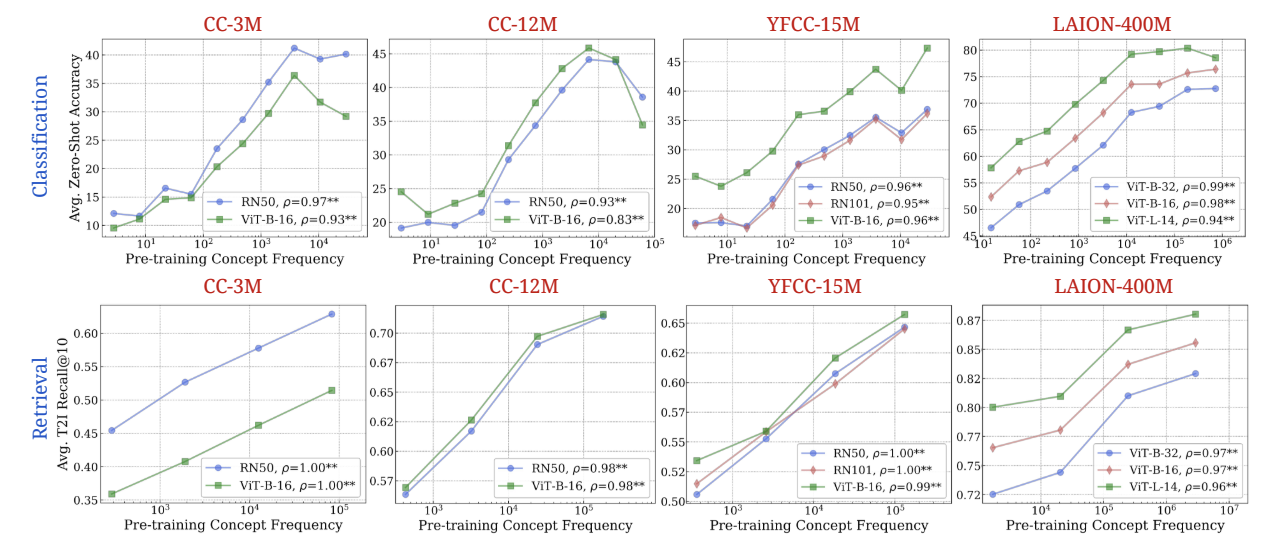
At the core of this issue is the scarcity of specialised data needed to train AI models effectively. As companies push the boundaries of AI, they are increasingly constrained by the availability of high-quality data. For AI to make accurate predictions or generate reliable outputs, it must be trained on a vast array of scenarios. However, in reality, the data necessary to cover every conceivable situation is finite. While this limitation might be less problematic in creative domains, where there’s often no clear-cut right or wrong answer, it becomes a significant hurdle in engineering. Programming, for instance, requires precise, correct solutions—there is little room for approximation or error.
In programming, most problems have a limited set of correct solutions, much like how there are only a few syntactically correct ways to write a loop in any given language. This constraint means that AI models are left with a relatively narrow pool of data to train on, especially as the complexity and specificity of the problem increase. As a result, the more niche and contextualised a problem becomes, the less effective the AI’s solution is likely to be. In essence, the further it moves from the data points it has been trained on, the more it struggles to provide a viable solution.
To put it simply, the heart of engineering is problem-solving. Problems are often deeply contextual, and therein lies the problem for AI. The datasets that exist for all the potential problems engineers could possibly need to solve do not exist at the scale necessary. Therefore, we rely on AI models making, in some sense, a “Zero-Shot” assumption about the problems we give them. However, underlying this performance are models that appear not to be scaling linearly but logarithmically. This means the effectiveness of AI in the domain of software engineering is unlikely to surpass the need for engineers to be replaced any time soon.
Real-World Performance
Supporting this notion of performance, current benchmarks, such as those provided by SWE-Bench, demonstrate that AI can only independently solve less than 20% of real-world GitHub issues (when looking at the “full” benchmark). When considering AI as a replacement for engineers, this statistic is telling. In real-world applications, this level of performance is far from adequate. Engineers are expected to solve complex problems with high accuracy, and relying on an AI that can barely tackle 20% of the issues it encounters would be impractical, if not outright disastrous.
Additionally, it’s important to remember that the ability to effectively use AI in the context of engineering, is itself, a skill that only trained engineers possess. Prompting an AI, understanding its limitations, and critically assessing its outputs are capabilities that stem from a deep understanding of the field. AI, no matter how advanced, still relies on the human touch to be truly effective. A key consideration stemming from this is the flawed idea that you can simply give an AI a basic prompt and receive perfect code, as even slight variations in wording can lead to significant errors.
This ambiguity inherently present in natural language makes building complex applications through simple prompts prone to error. As a result, engineers must often create more structured and detailed prompts, which ironically returns to the clarity and precision of traditional coding. Even then though, as explored before, the more detailed the prompt the further you drift from the AI’s models which might ultimately render the output unuseable anyway. This highlights the ongoing need for skilled engineers who can manage both the complexities of programming and AI interactions.
Synthetic Data
The evidence presented here also undermines a broader assumption that if we continue to increase the size of datasets, AI will eventually reach a level of “general intelligence” capable of addressing any problem it encounters. Whilst we may see future cycles significantly enhance the capabilities of AI, we are still a long way off this sci-fi prediction.
As touched on before, a fundamental threat AI currently faces is a lack of data. A recent study reveals that major AI companies are rapidly running out of the high quality data necessary for training their models. In turn this has led to the development of “Synthetic Data” which is where AI generates data with which to then train itself further. However, another recent study by Nature reveals how even small errors in the output of AI models can compound quickly after several generations. As the phrase goes, “garbage in, garbage out”.

AI is dead, long live AI!
Before it sounds like I’m entirely cynical about the development of AI, this is most definitely not the case. On the contrary, I believe AI is one of the most exciting developments in recent years. Without a doubt, it will change the way software is written and boost productivity. However, I present this case to offer a more skeptical viewpoint against the idea that AI presents any sort of existential threat to the profession, as has been suggested by Nvidia’s CEO.
On this point, I agree with Linus Torvalds, who highlighted in a recent interview that we have seen several productivity-boosting developments in the past decades, and each of them has led to more software being written, more problems being tackled, and more demand for software engineers.
What this all means though for engineers is that rather than replacing human expertise wholesale, AI’s current trajectory will for the forseeable future continue to serve as a powerful tool that complements and enhances the work of skilled engineers. For without engineers both the input and output of AI models remains largely redundant in the context of building complex software.