Writing a checkout bot with Puppeteer
With the new 5000 series GPUs from Nvidia on the horizon and supply looking to be in the single digits for some variants - no doubt securing one of these cards is going to be harder than finding a needle in a haystack, during a thunderstorm.
This got me thinking: for those fortunate enough to secure one of these cards, bots will likely play a big role (and no doubt scalping too). It made me curious about just how difficult it is to create one... so that’s exactly what I set out to do.
Just to be clear, I don’t support using bots to snatch up products for the purposes of scalping. My goal in sharing this process is to offer an insight in doing so demystify some of the technical aspects of how bots work.
Further disclaimer, the use of bots is highly discouraged by retailers and can result in having your account(s) suspended or IP address blocked. Although, this guide will illustrate some of the techniques bots use to circumvent these detections it does not guarantee results. It should go without saying that I accept no responsibility for any implementation in this guide.
Setup
First of all we need a way to automate the activity of a browser. We have a range options such as Playwright, Puppeteer, Selenium - however we're not simply using this for the purposes of E2E testing.
Instead we will be using rebrowser-puppeteer, which is a patched fork of Puppeteer, that obfuscates many of the flags that indicate the browser is being driven via automation.
Now these can be used to patch existing Playwright and Puppeteer projects - however it's easier in this case just to use the forked versions as we intend to use this only as a bot rather than for E2E.
To begin after creating a new project and running npm init we need to add both dependencies to our project:
npm i rebrowser-puppeteer
npm i rebrowser-puppeteer-core
We then need to add a new file called task.js, this will be where we actually write the automation script.
Configuration
Many sites these days deploy various heuristics to catch bots. Which means it essentially becomes a game of cat and mouse with bots trying to obfuscate their behaviour and appear as legitimate users.
This obfuscation is in part what rebrowser-puppeteer is doing. We can test the patches have worked by visiting the rebrowser bot detector in our task. We also need to setup a few things in our task.
const { default: puppeteer } = require("rebrowser-puppeteer");
(async () => {
const browser = await puppeteer.launch({
headless: false,
channel: "chrome",
args: ["--disable-blink-features=AutomationControlled"],
});
const page = await browser.newPage();
await page.setViewport({ width: 1080, height: 1024 });
await page.goto("https://bot-detector.rebrowser.net/");
await page.evaluate(() => window.dummyFn());
await page.evaluate(() => document.getElementById("detections-json"));
await page
.mainFrame()
.isolatedRealm()
.evaluate(() => document.getElementsByClassName("div"));
})();
In the task above, you can see we configure a few things. Such as launching "Chrome" rather than "Chromium" - a common flag that will be picked up by the user-agent of our browser - indicating we are likely a bot rather than a real user.
We also pass an argument --disable-blink-features=AutomationControlled which tells the browser to suppress the flag that it is being controlled via automation. The other steps simply initiate certain tests - which if our patches are successful shouldn't flag up any issue with the detector...

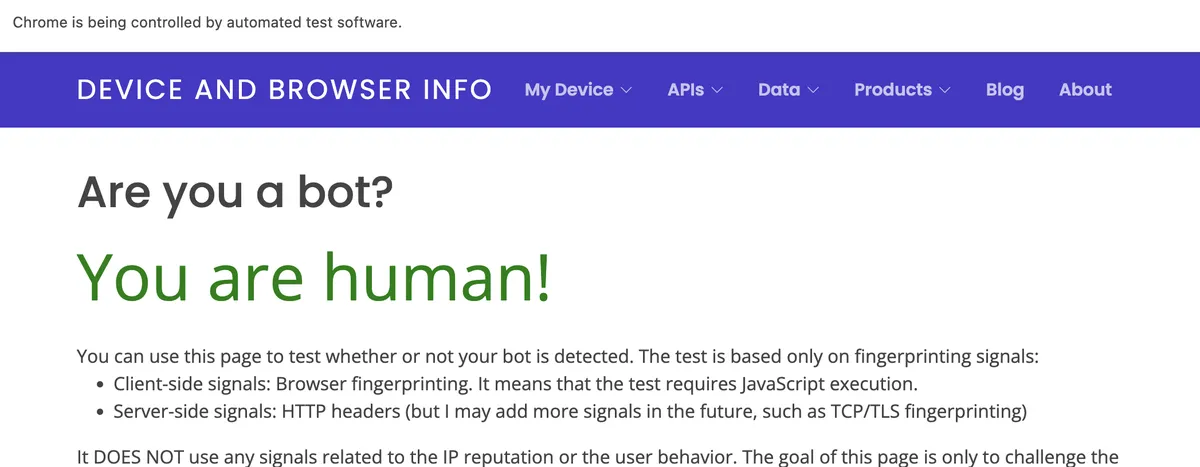
We can also check this detector here, which proudly claims we are not a bot!
Proxies
Right, that's automation and task configuration done. Next there is the obvious risk that in the game of cat and mouse, our IP address is blocked due to suspicious activity, such as repeatedly running a script.
In order to hide our real IP we can use a proxy address which will hide our IP when the task is running. There are several proxy services available so I won't go into too much detail about which to use. There are several reliable online proxy services where you can buy dozens of IPs for a small fee.
Once you have one setup, all you need to do is configure the task so that it uses the new proxy like so...
const browser = await puppeteer.launch({
headless: false,
channel: "chrome",
args: [
"--disable-blink-features=AutomationControlled",
"--proxy-server=http://${host}:${port}",
],
});
const page = await browser.newPage();
await page.authenticate({ username, password });
Once we have successfully authenticated with our proxy we can direct the task to a website such as this to confirm our new IP, which should now match the proxy.
Parallelisation
Now the last step of successful botting is being able to setup multiple bots to all run at the same time, either on the same site or across multiple different sites. For this we need to be able to run several tasks in parallel, to achieve this we can make use of Puppeteer Cluster.
Setting up Puppeteer Cluster requires a little more work as it uses the standard Puppeteer as a dependency. However, we are using the patched fork from rebrowser. Inside the package.json we will need to override this dependency.
"dependencies": {
"rebrowser-puppeteer": "^23.10.3",
"rebrowser-puppeteer-core": "^23.10.3",
"puppeteer-cluster": "^0.24.0"
},
"overrides": {
"puppeteer-cluster": {
"puppeteer": "npm:rebrowser-puppeteer@^23.3.1"
}
}
After running npm install we should be good to go...
const { default: puppeteer } = require("rebrowser-puppeteer");
const { Cluster } = require("puppeteer-cluster");
(async () => {
const cluster = await Cluster.launch({
concurrency: Cluster.CONCURRENCY_CONTEXT,
maxConcurrency: 2,
perBrowserOptions: {
headless: false,
channel: "chrome",
args: [
"--disable-blink-features=AutomationControlled",
"--proxy-server=http://${host}:${port}",
],
},
});
await cluster.task(async ({ page, data: url }) => {
await page.authenticate({ username, password }); // for the proxy
// do something with the page
});
cluster.queue("http://www.google.com/");
cluster.queue("http://www.wikipedia.org/");
// more websites
await cluster.idle();
await cluster.close();
})();
Now we can queue new sites for our task and even expand it further to accept parameters, for example different product variations.
Good bot
We've covered the basics here of building a checkout bot, but there are additional strategies beyond the technical scope covered here — such as using multiple mailing addresses or virtual credit cards.
You will notice, that I've intentionally avoided sharing the specific automation steps for any particular website, as I don’t want to encourage or enable the use of bots on specific retailers. The goal here isn’t to target individual platforms but to provide a general understanding of how these tools function. Though, at its core, this process is similar to any other automation task you might approach using Puppeteer, focusing on navigating websites and interacting with their elements programmatically.